In a previous post OpenShift Virtualization and Resource Overcommitment we discussed how OpenShift handles CPU and Memory resources, and more importantly how OpenShift Virtualization (OCPV) translates the Kubernetes concepts of CPU and Memory management into concepts that are more familiar to Virtualization Admins. If you haven’t already read that article I highly suggest going back and taking a look at it before proceeding here, as we will build on that knowledge in this post.
I assume you are here because you want to make the most of your physical resources and want to maximize your server resources by overcommiting memory and CPU. In this post we will talk about over-committing MEMORY and in an upcoming post we will talk about CPU.
So what does it mean to over-commit memory in OpenShift Virtualization. In a nut shell it is setting a ratio that says for every X amount of physical RAM in a cluster, allow for Y amount of virtual machine memory.
For example, you can set the OpenShift Memory overcommit to 150, or 150%, meaning that OpenShift Virtualization will assume that up to 50% of the overall amount of virtual machine memory can be swapped out to disk. In real world numbers, if you have a Physical host with 32GB of ram, and a .spec.higherWorkloadDensity.memoryOvercommitPercentage set to 150, OpenShift Virtualization will allow for up to 48GB of virtual machines on a given node.
WARNING: not every virtualized workload will work well in a overcommit scenario, and you may (will) have performance impacts when running under heavy load. The use of resource overcommiting should not be enabled without fully understanding what impacts it may have on your running systems.
There is another way to optimize memory as well. If you are running many instances of the same or similar VMs in your cluster, you can enable KSM or Kernel Same-page Merging which will look for memory pages that are the same between multiple virtual machines, and deduplicate this memory, only storing one copy of the memory. For example say you are running multiple Windows Server 2022 instances, much of the underlying active OS memory may be the same between all the VMS, so you can gain additional free memory by only storing these same pages once.
WARNING: there are significant security concerns with using KSM, and multiple exploits have been demonstrated that are enabled by using KSM. Only use KSM when you fully trust the VMs that are running in your environment. See KSM Security Issue - CVE-2024-0564 for additional details.
If achieving a higher density of virtual machines in your OpenShift Virtualization cluster is something that you want to achieve, then read on.
Testing Process
In order to see how this works, we are going to need a way to create multiple virtual machines, that start up and then consume memory. We could create multiple virtualMachine definitions, and apply them one at a time, but instead, we are going to use a feature of KubeVirt, called the VirtualMachinePool to test that our memory changes are working. What is a VirtualMachinePool? VirtualMachinePools are similar to Kubernetes Deployments but for VirtualMachines. We can define what a requested VirtualMachine should look like, and how many of those Virtual Machines we want, and Kubevirt will work to ensure that there are that many copies of the Virtual Machine running. This is a special use case for virtual machines, as it makes them much more ephemeral in nature allowing you to scale them up and down at a very quick rate. We will use this to scale up the number of VMs running in our cluster and scale them back down as needed.
WARNING: VirtualMachinePools are NOT a supported construct by Red Hat in OpenShift Virtualization. We are taking advantage of an upstream feature as part of this blog to simplify testing. Don’t go using VirtualMachinePools in OCPV for production, as Red Hat support will not be able to help you with this feature.
We will also take advantage of the ability to configure each of these VMs with some additional software and then run some specific commands to consume memory after they boot. We will do this using the cloudInitNoCloud to install the stress-ng application and then run two commands to quickly consume memory in each VM we create.
Create a file called vm-pool-fedora.yml with the following contents. We will start off with “0” replicas and then scale it up later.
apiVersion: pool.kubevirt.io/v1alpha1
kind: VirtualMachinePool
metadata:
name: vm-pool-fedora
spec:
replicas: 0
selector:
matchLabels:
kubevirt.io/vmpool: vm-pool-fedora
virtualMachineTemplate:
metadata:
creationTimestamp: null
labels:
kubevirt.io/vmpool: vm-pool-fedora
spec:
runStrategy: Always
template:
metadata:
creationTimestamp: null
labels:
kubevirt.io/vmpool: vm-pool-fedora
spec:
domain:
devices:
disks:
- disk:
bus: virtio
name: containerdisk
- disk:
bus: virtio
name: cloudinitdisk
memory:
guest: 4096Mi
terminationGracePeriodSeconds: 0
volumes:
- containerDisk:
image: quay.io/kubevirt/fedora-cloud-container-disk-demo
name: containerdisk
- cloudInitNoCloud:
userData: |
#cloud-config
password: fedora
chpasswd: { expire: False }
ssh_pwauth: True
disable_root: false
package_update: true
packages:
- stress-ng
runcmd:
- dd if=/dev/zero of=/run/memfill bs=1M count=1900
- stress-ng --vm-bytes $(awk '/MemAvailable/{printf "%d\n", $2 * 0.4;}' < /proc/meminfo)k --vm-hang 0 -m 1
name: cloudinitdisk
Let’s go ahead and create a new Project, and then apply our yaml
$ oc new-project overcommit
$ oc create -f vm-pool-fedora.yml
Now lets scale this VM pool up and create one replica:
$ oc scale vmpool vm-pool-fedora --replicas 1
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
Give the VM a few minutes to start, and then take a look at the memory usage in the UI console:
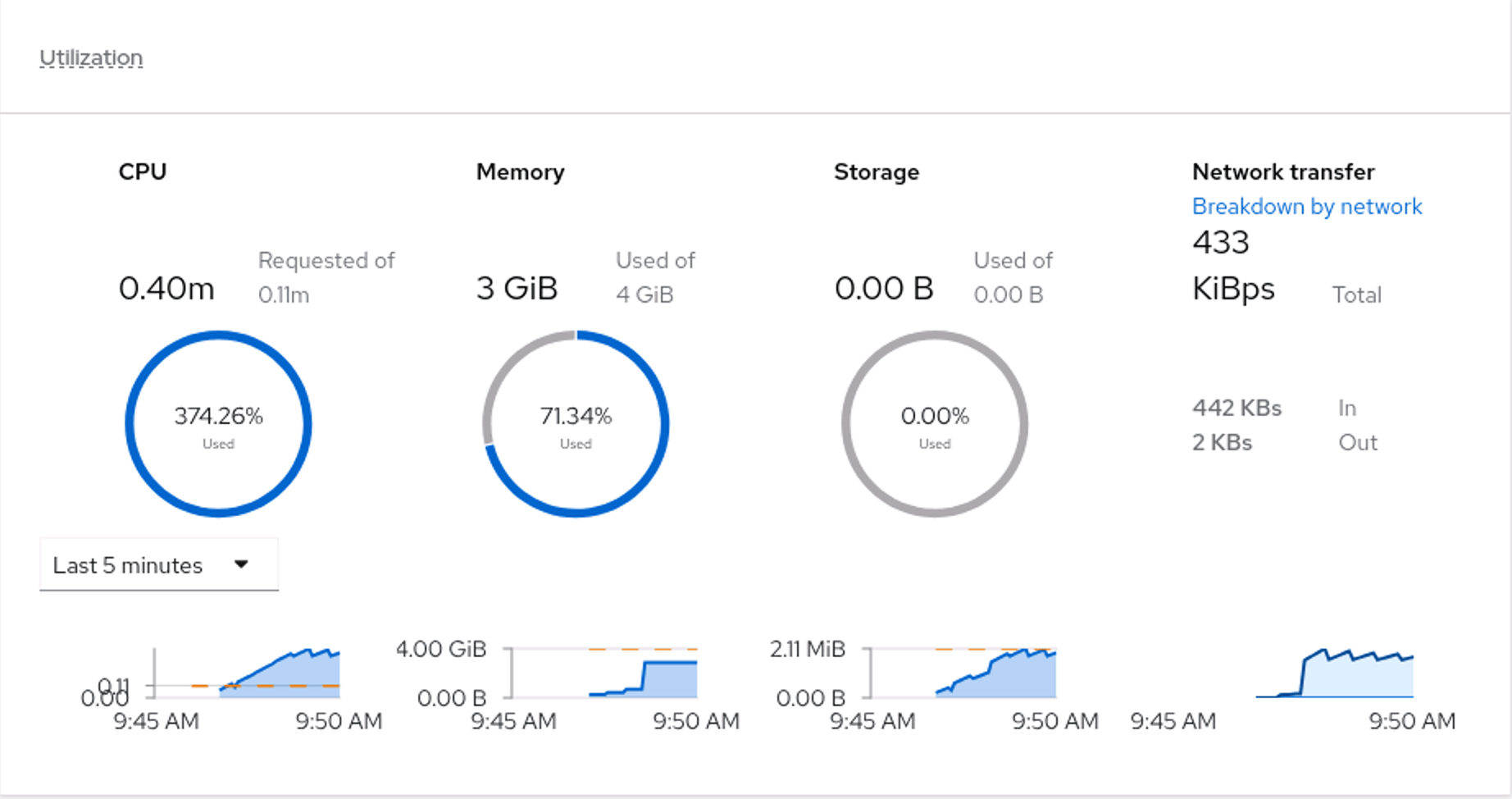
Go ahead and scale up the number of replicas on your cluster until you can no longer start the VMS. This will allow us to know what your cluster can run, without enabling all of the options to enable overcommit.
$ oc scale vmpool vm-pool-fedora --replicas 12
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
# wait a few minutes before running the next command
$ oc get virtualmachinepool
NAME DESIRED CURRENT READY AGE
vm-pool-fedora 12 12 10 17h
Reviewing the output we can see that 12 are Desired, but only 10 are ready. This is because I have run out of resources. So in my cluster, we can run a maximum of 10 VMs out of the box. We will scale our VirtualMachinePool down to 10, and then proceed onto the next steps.
$ oc scale vmpool vm-pool-fedora --replicas 10
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
# wait a few minutes before running the next command
$ oc get virtualmachinepool
NAME DESIRED CURRENT READY AGE
vm-pool-fedora 10 10 10 17h
So now we have a way to quickly create new VMs and consume memory, allowing us to test out and validate that the changes we are going to make work.
Enabling KSM
We will start our adventure by enabling KSM. We can enable KSM through the OpenShift GUI, or from the command line. The choice of how you proceed is up to you.
**NOTE: KSM is enabled at the cluster level, and by default effects all VMs in your cluster. It is possible to enable KSM to work on only a subset of Nodes, by using the node selection syntax to the ksmConfiguration.nodeLabelSelector field and then labeling the appropriate labels. You can also add selectors to your VMs to avoid nodes that have `kubevirt.io/ksm-enabled: “true”
Enabling KSM from the GUI
To enable KSM on your cluster from the GUI
- Log into the OpenShift Console as a cluster administrator
- From the side menu, click Virtualization → Overview.
- Select the Settings tab.
- Select the Cluster tab.
- Expand Resource management.
- Enable the feature for all nodes:

Enabling KSM from the CLI
We can also make this change from the command line. Use the command oc edit hyperconverged kubevirt-hyperconverged -n openshift-cnv and then add the highlighted lines shown below.
apiVersion: hco.kubevirt.io/v1beta1
kind: HyperConverged
metadata:
name: kubevirt-hyperconverged
namespace: openshift-cnv
spec:
configuration:
ksmConfiguration:
nodeLabelSelector: {}Validating our KSM Change
So in our environment we have 10 virtual machines running in our pool. In order to see KSM in action, we need to scale down our pool, and then scale it back up as KSM will not activate on running VMs.
$ oc scale vmpool vm-pool-fedora --replicas 0
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
# wait for all vms to be stopped before proceeding with the next command
$ oc scale vmpool vm-pool-fedora --replicas 10
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
We can now check and see if KSM is being effective. We will run an oc debug node command to check on the kernel level stats of the ksm feature. (note that you will need to give it a few minutes before checking the stats below):
$ oc debug node/acm-775pj-worker-zzbff -- cat /sys/kernel/mm/ksm/pages_sharing
Temporary namespace openshift-debug-8kv8w is created for debugging node...
Starting pod/acm-775pj-worker-zzbff-debug-7ndl8 ...
To use host binaries, run `chroot /host`
1792850
Removing debug pod ...
Temporary namespace openshift-debug-8kv8w was removed.
So on this node, we have 1,792,850 pages that are currently shared. On an x86_64 machine a page is 4096 Bytes, so some quick math gives us 7,343,513,600 Bytes, or 7.3Gb of memory that is shared by this machine.
GREAT, so on this one machine we just saved 7Gb and should be able to scale up more VMs right …. well No.
If you try to scale up our VirtualMachinePool, you will find that you can’t get any more VMs running. This is because we are not currently configured to overcommit memory. This is a setting that we need to enable in OpenShift Virtualization. That being said, we are NOT ready to do this yet … and here is why.
What happens when those shared memory pages are no longer “share-able”. Our VMs will start to expand into our limited physical memory, and eventually we will run out of physical memory. At that point, the Linux OOM killer will take over and start terminating VMs, and we don’t want our VMs just going away. So now we need a secondary memory space to work with. This is where SWAP space comes into play.
Enabling SWAP and the WASP Agent
While enabling KSM may get you a little extra memory, you will most likely not see huge gains by just enabling KSM in the real world. In order to see larger gains, we are going to need to enable SWAP on the nodes, will allow us to gain much higher utilization of our physical resources.
In order to get additional usable memory in our cluster, we are going to enable swap memory, allowing the Kubernetes Worker nodes to “swap out” inactive memory to local disk. When we enable swap it will only be available to virtual machines that are of “Burstable” QoS. If you have virtual machines that you do not want to be swapped out you can set the QoS on the VM to Guaranteed.
Configure the Worker Node Kubelet
To start we need to enable the nodes to use swap. Create a file called kubelet-swapon.yaml with the following contents:
apiVersion: machineconfiguration.openshift.io/v1
kind: KubeletConfig
metadata:
name: custom-swap-config
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ''
kubeletConfig:
failSwapOn: false
NOTE: This will reboot all worker nodes in your cluster. We will be making additional changes that will also require a reboot, but they must be applied in order.
Apply this file to your cluster with oc apply -f kubelet-swapon.yaml
We now need to wait for this change to take effect. We can do this by running the following command and waiting for it to complete.
$ oc wait mcp worker --for condition=Updated=True --timeout=-1s`.
machineconfigpool.machineconfiguration.openshift.io/worker condition met
WARNING: Ensure that the KubeletConfig above has been applied to all nodes prior to moving onto the next step. Enabling swap prior to the KubeletConfig change will cause your nodes to be inoperable!
Enable Swap on the Linux Node
With the Kubelet configured to use swap, we now need to make the swap space available. This will be done with a machineConfig. Create a file called 90-worker-swap.yaml
apiVersion: machineconfiguration.openshift.io/v1
kind: MachineConfig
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 90-worker-swap
spec:
config:
ignition:
version: 3.4.0
systemd:
units:
- contents: |
[Unit]
Description=Provision and enable swap
ConditionFirstBoot=no
[Service]
Type=oneshot
Environment=SWAP_SIZE_MB=12000
ExecStart=/bin/sh -c "sudo dd if=/dev/zero of=/var/tmp/swapfile count=${SWAP_SIZE_MB} bs=1M && \
sudo chmod 600 /var/tmp/swapfile && \
sudo mkswap /var/tmp/swapfile && \
sudo swapon /var/tmp/swapfile && \
free -h && \
sudo systemctl set-property --runtime system.slice MemorySwapMax=0 IODeviceLatencyTargetSec=\"/ 50ms\""
[Install]
RequiredBy=kubelet-dependencies.target
enabled: true
name: swap-provision.service
NOTE: creating a
swapfileon the root disk is NOT a recommended or performant way to handle this in Production. You should have a separate disk (preferably NVMe) that is used for your swap file. Make sure you update the yaml above to use a dedicated disk if doing this for production use cases.
The SWAP_SIZE_MB variable in the above file needs to be updated to reflect the proper amount of swap to create. If you plan to have a over-commit ratio of 150%, then you need to ensure that the SWAP_SIZE_MB is 50% of the total ram in the system. So for example, if your worker nodes have 24GB of ram, the SWAP_SIZE_MB should be set to 12000.
Once you have calculated your swap size and updated the template above, apply to your cluster with oc apply -f 90-worker-swap.yaml.
We now need to wait for this change to take effect. We can do this by running the following command and waiting for it to complete.
$ oc wait mcp worker --for condition=Updated=True --timeout=-1s`.
machineconfigpool.machineconfiguration.openshift.io/worker condition met
Deploy WASP
What is WASP? WASP is a utility that will run on all nodes that run Virtual Machines, to allow Virtual Machine pods (and ONLY Virtual Machine Pods) to swap out to disk. It also monitors the use of SWAP by the virtual machines, and will trigger VM evictions when swap usage exceeds defined thresholds. If you want to learn more about WASP I suggest checking out the upstream GitHub project wasp-agent
I have simplified the deployment of the WASP agent by pulling all the YAML together into one file. You can download the YAML which will deploy most of the WASP utility from here: Deploying WASP.
If you want to see everything that is a part of this, check the official documentation Using wasp-agent to increase VM workload density
Let’s go ahead and download the YAML and apply to to the cluster, and add the WASP user to the privileged SCC:
$ wget https://gist.githubusercontent.com/xphyr/0318c2ed424868a63ca6144b1f29f6bc/raw/5be46a5d33854a99b710e8fdd1d19962176489a5/wasp-deploy.yaml
$ oc apply -f wasp-deploy.yaml
namespace/wasp created
serviceaccount/wasp created
clusterrolebinding.rbac.authorization.k8s.io/wasp created
daemonset.apps/wasp-agent created
$ oc adm policy add-scc-to-user -n wasp privileged -z wasp
clusterrole.rbac.authorization.k8s.io/system:openshift:scc:privileged added: "wasp"
We can check that the daemonset has rolled out and is ready before continuing:
$ oc get daemonset -n wasp
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
wasp-agent 4 4 4 4 4 <none> 4h12m
In this case we can see that there are 4 instances of the wasp-agent running to correspond with the four worker nodes that I have in my cluster.
Testing this all out
So, previously we were only able to run a maximum of 10 virtual machines on my cluster. With our cluster now configured with KSM, Swap and configuring OpenShift Virtualization for 150% overcommit, what can we do? Lets try scaling up our VirtualMachinePool to 20 VMs.
$ oc scale vmpool vm-pool-fedora --replicas 20
virtualmachinepool.pool.kubevirt.io/vm-pool-fedora scaled
Lets take a look at what we get With swap on:
$ oc get virtualmachinepool
NAME DESIRED CURRENT READY AGE
vm-pool-fedora 20 20 17 19h
So we can now see that instead of just 10 vms, we have 17 running! We can also take a look at our swap usage on the nodes and see that some of our VM memory is being pushed out to disk:
$ oc debug node/acm-775pj-worker-l5hmt -- free -m
Temporary namespace openshift-debug-6ptcq is created for debugging node...
Starting pod/acm-775pj-worker-l5hmt-debug-9gspn ...
To use host binaries, run `chroot /host`
total used free shared buff/cache available
Mem: 24032 12759 6814 15 4880 11272
Swap: 11999 4323 7676
As shown above, we have swapped out 4.3Gb to disk.
One Final Note
If you have been using OpenShift Virtualization for a while, you may have VMs that do not appear to be effected by memory overcommit. This occurs when you define your virtual machine memory using spec.domain.resources.requests.memory. In order for your virtual machines to take advantage of memory overcommit, you will need to update your virtualMachine definitions to use spec.domain.memory.guest. If you are using VirtualMachineInstanceTypes, you will not run into this issue.
Conclusion
In this blog post we have seen how it is possible to overcommit memory within OpenShift Virtualization, through the use of KSM, Linux SWAP and the WASP Agent. How you go about implementing this in your environment is up to you. This should not just be applied to a cluster without understanding the overall impact it will have on your virtual machine workloads. Once you have experimented with it, and understand its performance impacts to YOUR workloads, it can be enabled to make better use of your hardware investments.
References
Configuring higher VM workload density